
O aprendizado profundo pode parecer mágica! Eu tenho sentimentos mágicos quando vejo a rede neural fazendo algo criativo, como aprender a produzir pinturas como um artista. A tecnologia por trás disso é chamada de Redes Geradoras Adversas e, nesta postagem, examinaremos como treinar essa rede no serviço do Azure Machine Learning.
Se você acompanhou minhas postagens anteriores sobre o Azure ML (sobre o uso no VS Code e o envio de experimentos e a otimização de hiperparâmetro), deve saber que é bastante conveniente usar o Azure ML para quase todas as tarefas de treinamento. No entanto, todos os exemplos até agora foram baseados no uso de pequenos conjunto de dados do MNIST. Hoje, vamos nos concentrar em problemas reais, ou seja, como criar pinturas artificiais como as seguintes:

Flores, 2019, A arte do artificial
keragan treinou nas flores do WikiArt

Rainha do caos, 2019,
keragan treinou nos retratos do WikiArt
Essas pinturas foram produzidas depois de treinar a rede em pinturas do WikiArt. Se você quiser reproduzir os mesmos resultados, talvez seja necessário coletar o conjunto de dados por conta própria, por exemplo, usando o Recuperador do WikiArt ou emprestando coleções existentes do Conjunto de dados do WikiArt ou do Projeto GANGogh.
Coloque as imagens que você deseja treinar em algum lugar do diretório dataset. Para treinamento em flores, aqui está como pode ser a aparência de algumas dessas imagens:
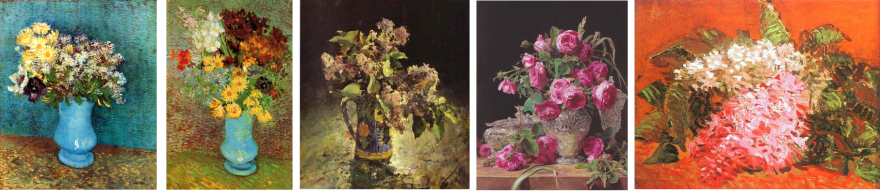
Precisamos do nosso modelo de rede neural para aprender tanto uma composição de alto nível de buquê de flores e vaso, quanto um estilo de pintura de baixo nível, com manchas de pintura e textura em tela.
Redes Geradoras Adversas
Essas pinturas foram geradas usando Redes Geradoras Adversas ou GANs, em sua forma abreviada. Neste exemplo, usaremos minha implementação simples de GAN em Keras chamada keragan e veremos algumas partes de código simplificadas.
 shwars / keragan
shwars / keragan
Implementação de GANs no Keras
As GANs são compostas por dois tipos de redes:
- Geradoras, que geram imagens de acordo com algum vetor de ruído de entrada
- Discriminadoras, cuja função é diferenciar entre pinturas reais e “falsas” (geradas)

O treinamento da GAN envolve as seguintes etapas:
- Obter uma série de imagens geradas e reais:
noise = np.random.normal(0, 1, (batch_size, latent_dim)) gen_imgs = generator.predict(noise)
imgs = get_batch(batch_size)
- Treinar a rede discriminadora para diferenciar melhor entre esses dois tipos de imagem. Observe que fornecemos
onesezerosao vetor como respostas esperadas:
d_loss_r = discriminator.train_on_batch(imgs, ones) d_loss_f = discriminator.train_on_batch(gen_imgs, zeros) d_loss = np.add(d_loss_r , d_loss_f)*0.5- Treinar o modelo combinado, a fim de melhorar a rede geradora:
g_loss = combined.train_on_batch(noise, ones)
Durante essa etapa, a rede discriminadora não é treinada, pois seus pesos são explicitamente congelados durante a criação do modelo combinado:
discriminator = create_discriminator()
generator = create_generator()
discriminator.compile(loss='binary_crossentropy', optimizer=optimizer,
metrics=['accuracy'])
discriminator.trainable = False
z = keras.models.Input(shape=(latent_dim,))
img = generator(z)
valid = discriminator(img)
combined = keras.models.Model(z, valid)
combined.compile(loss='binary_crossentropy', optimizer=optimizer)
Modelo discriminador
Para diferenciar uma imagem real de uma imagem falsa, usamos a arquitetura CNN (Rede Neural Convolucional) tradicional. Portanto, para a imagem do tamanho 64×64, teremos algo assim:
discriminator = Sequential()
for x in [16,32,64]: # number of filters on next layer
discriminator.add(Conv2D(x, (3,3), strides=1, padding="same"))
discriminator.add(AveragePooling2D())
discriminator.addBatchNormalization(momentum=0.8))
discriminator.add(LeakyReLU(alpha=0.2))
discriminator.add(Dropout(0.3))
discriminator.add(Flatten())
discriminator.add(Dense(1, activation='sigmoid'))
Temos 3 camadas de convolução, que fazem o seguinte:
- A imagem original com forma 64x64x3 é passada por 16 filtros, resultando na forma 32x32x16. Para diminuir o tamanho, usamos
AveragePooling2D. - A próxima etapa converte o tensor 32x32x16 em 16x16x32
- Por fim, após a próxima camada de convolução, terminamos com o tensor com forma 8x8x64.
Sobre essa base convolucional, colocamos um classificador de regressão logística simples (também conhecido como camada densa de um neurônio).
Modelo gerador
O modelo gerador é um pouco mais complicado. Primeiro, imagine que desejamos converter uma imagem em algum tipo de vetor de recursos de comprimento latent_dim=100. Usaremos o modelo de rede convolucional semelhante ao discriminador, acima, mas a camada final seria uma camada densa com tamanho 100.
O gerador faz o oposto – converte o vetor de tamanho 100 em uma imagem. Isso envolve um processo chamado de deconvolução, que é basicamente uma convolução invertida. Juntamente com UpSampling2D, eles fazem com que o tamanho do tensor aumente em cada camada:
generator = Sequential()
generator.add(Dense(8 * 8 * 2 * size, activation="relu",
input_dim=latent_dim))
generator.add(Reshape((8, 8, 2 * size)))
for x in [64;32;16]:
generator.add(UpSampling2D())
generator.add(Conv2D(x, kernel_size=(3,3),strides=1,padding="same"))
generator.add(BatchNormalization(momentum=0.8))
generator.add(Activation("relu"))
generator.add(Conv2D(3, kernel_size=3, padding="same"))
generator.add(Activation("tanh"))
Na última etapa, acabamos com um tensor de tamanho 64x64x3, que é exatamente o tamanho da imagem que precisamos.
Observe que a função de ativação final é tanh, que fornece uma saída no intervalo de [-1; 1] – o que significa que precisamos dimensionar as imagens de treinamento originais segundo esse intervalo. Todas essas etapas para preparação das imagens são gerenciadas pela classe ImageDataset, que não abordaremos em detalhes nesse momento.
Script de treinamento para o Azure ML
Agora que temos todas as peças para treinar a GAN em conjunto, estamos prontos para executar esse código no Azure ML como um experimento. O código que veremos aqui está disponível no GitHub:
CloudAdvocacy / AzureMLStarter
Este é um tutorial para ajudar você a começar a usar o serviço do Azure ML
Há uma coisa importante a ser observada, no entanto: normalmente, ao executar um experimento no Azure ML, queremos acompanhar algumas métricas, como precisão ou perda. Podemos registrar esses valores durante o treinamento usando run.log (conforme descrito em minha postagem anterior) e ver como essa métrica é alterada durante o treinamento no Portal do Azure ML.
Em nosso caso, em vez da métrica numérica, estamos interessados nas imagens visuais que nossa rede gera em cada etapa. Inspecionar essas imagens enquanto o experimento está em execução pode nos ajudar a decidir se desejamos encerrar nosso experimento, alterar os parâmetros ou continuar.
O Azure ML dá suporte ao registro em log de imagens, além de números, conforme descrito aqui. Podemos registrar as imagens representadas como np-arrays ou quaisquer plotagens produzidas por matplotlib, portanto, plotaremos três imagens de exemplo em um gráfico. Essa plotagem será gerenciada na função de retorno de chamada callbk, que é chamada por keragan após cada período de treinamento:
defcallbk(tr):if tr.gan.epoch % 20 == 0:
res = tr.gan.sample_images(n=3)
fig,ax = plt.subplots(1,len(res))
for i,v in enumerate(res):
ax[i].imshow(v[0])
run.log_image("Sample",plot=plt)
Portanto, o código de treinamento real terá a seguinte aparência:
gan = keragan.DCGAN(args)
imsrc = keragan.ImageDataset(args)
imsrc.load()
train = keragan.GANTrainer(image_dataset=imsrc,gan=gan,args=args)
train.train(callbk)
Observe que keragan dá suporte à análise automática de muitos parâmetros de linha de comando que podemos passar para ele por meio da estrutura args, e isso é o que torna esse código tão simples.
Iniciar o experimento
Para enviar o experimento ao Azure ML, usaremos um código semelhante àquele discutido na postagem anterior sobre o Azure ML. O código está localizado dentro de [submit_gan.ipynb][https://github.com/CloudAdvocacy/AzureMLStarter/blob/master/submit_gan.ipynb] e ele começa com etapas familiares:
- Conectar-se ao workspace usando
ws = Workspace.from_config() - Conectar-se ao cluster de cálculo:
cluster = ComputeTarget(workspace=ws, name='My Cluster'). Aqui, precisamos de um cluster de VMs habilitadas para GPU, como NC6. - Carregar o conjunto de dados ao armazenamento de dados padrão do Workspace do ML
Depois disso, podemos enviar o experimento usando o seguinte código:
exp = Experiment(workspace=ws, name='KeraGAN')
script_params = {
'--path': ws.get_default_datastore(),
'--dataset' : 'faces',
'--model_path' : './outputs/models',
'--samples_path' : './outputs/samples',
'--batch_size' : 32,
'--size' : 512,
'--learning_rate': 0.0001,
'--epochs' : 10000
}
est = TensorFlow(source_directory='.',
script_params=script_params,
compute_target=cluster,
entry_script='train_gan.py',
use_gpu = True,
conda_packages=['keras','tensorflow','opencv','tqdm','matplotlib'],
pip_packages=['git+https://github.com/shwars/[email protected]']
run = exp.submit(est)
Nesse caso, passamos model_path=./outputs/models e samples_path=./outputs/samples como parâmetros, o que fará com que os modelos e as amostras gerados durante o treinamento sejam gravados nos diretórios correspondentes dentro do experimento do Azure ML. Esses arquivos estarão disponíveis por meio do portal do Azure ML e também poderão ser baixados programaticamente depois (ou mesmo durante o treinamento).
Para criar o avaliador que pode ser executado na GPU sem problemas, usamos o avaliador interno Tensorflow. É muito semelhante ao Estimator genérico, mas também fornece algumas opções prontas para o uso para treinamento distribuído. Você pode ler mais sobre como usar diferentes avaliadores na documentação oficial.
Outro ponto interessante aqui é como instalamos a biblioteca keragan, diretamente do GitHub. Embora também possamos instalar a biblioteca do repositório PyPI, eu queria demonstrar que a instalação direta do GitHub também é compatível e você pode até mesmo indicar uma versão da biblioteca, uma marcação ou uma ID de confirmação específica.
Depois que o experimento estiver em execução por algum tempo, deve ser possível observar as imagens de exemplo que estão sendo geradas no portal do Azure ML:
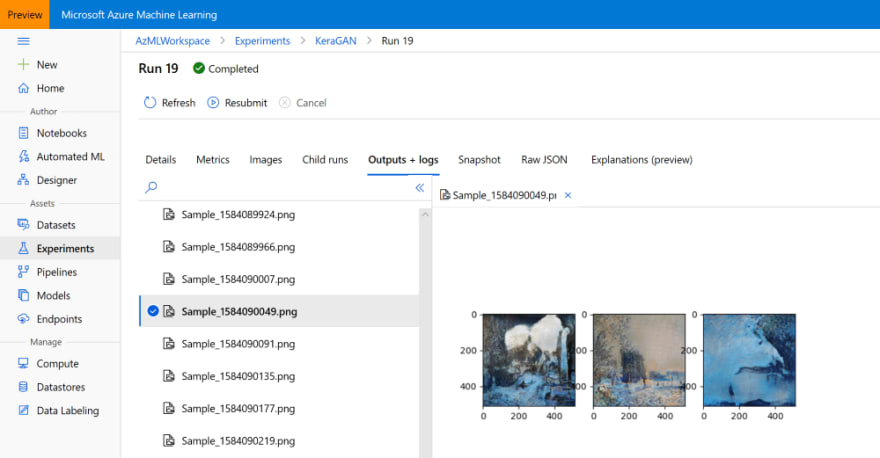
Executar muitos experimentos
Na primeira vez que executamos o treinamento da GAN, podemos não obter resultados excelentes, por vários motivos. Em primeiro lugar, a taxa de aprendizado parece ser um parâmetro importante e uma taxa de aprendizado muito alta pode levar a resultados insatisfatórios. Portanto, para obter os melhores resultados, talvez seja necessário executar uma série de experimentos.
Os parâmetros que devemos variar são os seguintes:
--sizedetermina o tamanho da imagem, que deve ser uma potência de 2. Tamanhos pequenos, como 64 ou 128, permitem experimentos rápidos, ao passo que tamanhos grandes (até 1024) são bons para a criação de imagens de qualidade superior. Qualquer coisa acima de 1024 provavelmente não produzirá bons resultados, pois para treinar GANs de grandes resoluções são necessárias técnicas especiais, como o crescimento progressivo--learning_rateé, surpreendentemente, um parâmetro muito importante, especialmente com resoluções mais altas. Taxas de aprendizado menores geralmente fornecem melhores resultados, mas o treinamento ocorre muito devagar.--dateset. Talvez seja interessante carregar imagens de diferentes estilos em pastas distintas do armazenamento de dados do Azure ML e começar a treinar vários experimentos simultaneamente.
Como já sabemos como enviar o experimento programaticamente, deve ser fácil encapsular esse código em alguns loops for-para executar limpezas paramétricas. Então, você pode verificar manualmente por meio do portal do Azure ML quais experimentos estão bem encaminhados para produzir bons resultados e encerrar todos os outros experimentos para economizar recursos. Ter um cluster com algumas VMs proporciona a você a liberdade de iniciar alguns experimentos ao mesmo tempo sem ter que esperar.
Obter os resultados do experimento
Quando estiver satisfeito com os resultados, faz sentido obter os resultados do treinamento no formulário ou nos arquivos do modelo e as imagens de exemplo. Eu mencionei que, durante o treinamento, nosso script de treinamento armazenaram os modelos no diretório outputs/models e as imagens de exemplo – em outputs/samples. Você pode navegar nesses diretórios no portal do Azure ML e baixar manualmente os arquivos desejados:
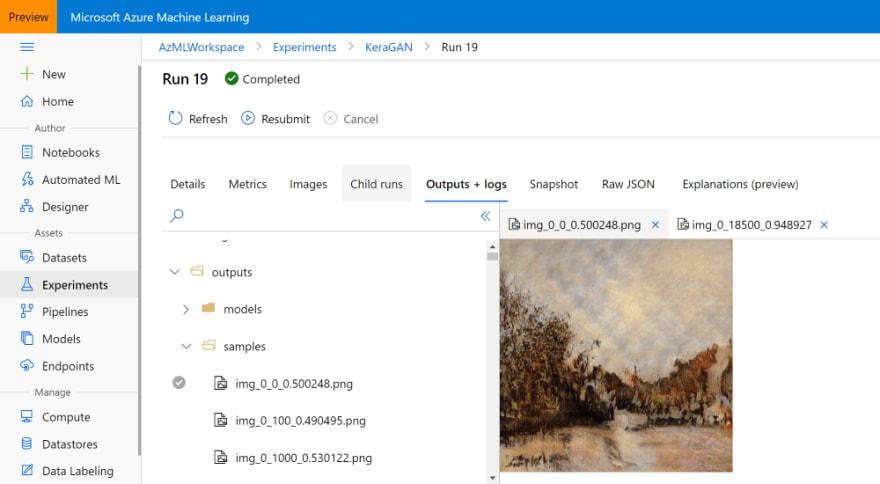
Você também pode fazer isso programaticamente, especialmente se quiser baixar todas as imagens produzidas durante diferentes períodos. O objeto run que você obteve durante o envio do experimento fornecerá acesso a todos os arquivos armazenados como parte dessa execução e você poderá baixá-los da seguinte maneira:
run.download_files(prefix='outputs/samples')
Isso criará o diretório outputs/samples dentro do diretório atual e baixará todos os arquivos do diretório remoto com o mesmo nome.
Se você perder a referência à execução específica dentro do notebook (isso pode acontecer, já que a maioria dos experimentos é de longo prazo), poderá recriá-la com base na ID de execução, que pode ser pesquisada no portal:
run = Run(experiment=exp,run_id='KeraGAN_1584082108_356cf603')
Também podemos obter os modelos que foram treinados. Por exemplo, vamos baixar o modelo de gerador final e usá-lo para gerar uma porção de imagens aleatórias. Podemos obter todos os nomes de arquivo associados ao experimento e filtrar apenas aqueles que representam modelos de gerador:
fnames = run.get_file_names()
fnames = filter(lambda x : x.startswith('outputs/models/gen_'),fnames)
Eles todos se parecerão com outputs/models/gen_0.h5, outputs/models/gen_100.h5 e assim por diante. Precisamos descobrir o número de período máximo:
no = max(map(lambda x: int(x[19:x.find('.')]), fnames))
fname = 'outputs/models/gen_{}.h5'.format(no)
fname_wout_path = fname[fname.rfind('/')+1:]
run.download_file(fname)
Isso baixará o arquivo com o número de período mais alto do diretório local e também armazenará o nome desse arquivo (sem o caminho do diretório) em fname_wout_path.
Gerar novas imagens
Depois de obtermos o modelo, precisamos apenas carregá-lo no Keras, descobrir o tamanho da entrada e fornecer o vetor aleatório dimensionado corretamente como entrada para produzir uma nova pintura aleatória gerada pela rede:
model = keras.models.load_model(fname_wout_path)
latent_dim=model.layers[0].input.shape[1].value
res = model.predict(np.random.normal(0,1,(10,latent_dim)))
A saída da rede do gerador está no intervalo [-1; 1]. Portanto, precisamos dimensioná-la linearmente para o intervalo [0; 1] para ser exibida corretamente por matplotlib:
res = (res+1.0)/2
fig,ax = plt.subplots(1,10,figsize=(15,10))
for i in range(10):
ax[i].imshow(res[i])
Este é o resultado que obteremos:
Observe algumas das melhores imagens produzidas durante este experimento:


Primavera colorida, 2020
Zona rural, 2020


Através do vidro congelado, 2020
Paisagem de verão, 2020
Siga @art_of_artificial no Instagram – Eu tento publicar novas imagens produzidas pela GAN periodicamente.
Observar o processo de aprendizado
Também é interessante observar o processo de como a rede GAN aprende gradualmente. Eu explorei essa noção de aprendizado na minha exposição A arte do artificial. Aqui estão alguns vídeos que mostram esse processo:
Para se aprofundar
Nesta postagem, eu descrevi como funciona a GAN e como podemos treiná-la usando o Azure ML. Isso definitivamente abre muito espaço para experimentação, mas também traz grandes oportunidades de aprofundamento. Durante esse experimento, criamos os trabalhos artísticos originais gerados por meio da inteligência artificial. Mas eles podem ser considerados ARTE? Discutirei isso em uma das minhas próximas postagens…
Agradecimentos
Ao produzir a biblioteca keragan, eu me inspirei bastante neste artigo, na implementação DCGAN de Maxime Ellerbach e também, em parte, no projeto GANGogh. Muitas arquiteturas GAN diferentes implementadas no Keras são apresentadas aqui.


