
A maioria dos modelos de machine learning é bastante complexa contendo vários elementos que chamamos de hiperparâmetros, como camadas em uma rede neural, número de neurônios nas camadas ocultas ou taxa de abandono. Para criar o melhor modelo, precisamos escolher a combinação desses hiperparâmetros que funciona melhor. Normalmente, esse processo é bastante entediante e consome bastante recursos, mas o Azure Machine Learning pode torná-lo muito mais simples.
Em minha postagem anterior sobre Azure Machine Learning, descrevi como começar a usar o Azure ML por meio do Visual Studio Code. Continuaremos a explorar o exemplo descrito lá, treinando um modelo simples para fazer a classificação de dígitos no conjunto de dados do MNIST.
Automação com o SDK do Python do Azure ML
A otimização de hiperparâmetros significa que precisamos executar um grande número de experimentos com parâmetros diferentes. Sabemos que o Azure ML nos permite acumular todos os resultados do experimento (incluindo as métricas obtidas) em um único lugar, o Workspace do Azure ML. Basicamente, tudo o que precisamos fazer é enviar muitos experimentos com hiperparâmetros diferentes.
Em vez de fazer isso manualmente por meio do VS Code, podemos fazer programaticamente por meio do SDK do Python do Azure ML. Todas as operações, incluindo a criação do cluster, a configuração do experimento e a obtenção dos resultados, podem ser feitas com algumas linhas de código do Python. Esse código pode parecer um pouco complexo a princípio, mas depois de escrever (ou entender) uma vez, você verá o quanto ele é prático de usar.
Executar o código
O código ao qual me referi nesta postagem está disponível no repositório do Azure ML Starter. A maior parte do código que descreverei aqui está contida dentro do notebook submit.ipynb. Você pode executá-lo de algumas maneiras:
- Se você tiver um ambiente local do Python instalado, poderá simplesmente iniciar a instância local do Jupyter executando
jupyter notebookno diretório comsubmit.ipynb. Nesse caso, você precisa instalar o SDK do Azure ML executandopip install azureml-sdk - Carregando-o para a seção Notebook no Portal do Azure ML e executando-o lá. Você também precisará criar uma VM para executar notebooks do Workspace do Azure ML, mas isso pode ser feito por meio da mesma interface da Web de maneira muito simples.
- Carregando-o no Azure Notebooks
Se você preferir trabalhar com arquivos Python sem formatação, o mesmo código também estará disponível em submit.py.
Conectar-se ao workspace e ao cluster
A primeira coisa que você precisa fazer ao usar o SDK do Python do Azure ML é conectar-se ao Workspace do Azure ML. Para fazer isso, você precisa fornecer todos os parâmetros necessários, como ID da assinatura, workspace e nome do grupo de recursos mais informações sobre isso na documentação:
ws = Workspace(subscription_id,resource_group,workspace_name)
A maneira mais fácil de se conectar é armazenar todos os dados necessários dentro do arquivo config.json e, em seguida, instanciar a referência do workspace da seguinte maneira:
ws = Workspace.from_config()
Você pode baixar o arquivo config.json do seu portal do Azure navegando até a página do Workspace do Azure ML:

Depois de obtermos a referência do workspace, podemos obter a referência para o cluster de computação que desejamos usar:
cluster_name = "AzMLCompute"
cluster = ComputeTarget(workspace=ws, name=cluster_name)
Esse código pressupõe que você já tenha criado o cluster manualmente (conforme descrito na postagem anterior). Você também pode criar o cluster com os parâmetros necessários programaticamente. O código correspondente é fornecido em submit.ipynb.
Preparar e carregar o conjunto de dados
Em nosso exemplo de treinamento do MNIST, baixamos o conjunto de dados do MNIST do repositório OpenML na Internet dentro do script de treinamento. Se quiséssemos repetir o experimento muitas vezes, faria sentido armazenar os dados em algum lugar próximo ao computador: dentro do Workspace do Azure ML.
Primeiro, vamos criar o conjunto de dados do MNIST como um arquivo em disco na pasta dataset. Para fazer isso, execute o arquivo create_dataset.py e observe como a pasta dataset é criada e todos os arquivos de dados são armazenados lá.
Cada Workspace do Azure ML tem um armazenamento de dados padrão associado a ele. Para carregar nosso conjunto de dados ao armazenamento de dados padrão, precisamos de apenas algumas linhas de código:
ds = ws.get_default_datastore()
ds.upload('./dataset', target_path='mnist_data')
Enviar experimentos automaticamente
Neste exemplo, treinaremos o modelo de rede neural de duas camadas no Keras, usando o script de treinamento train_keras.py. Esse script pode obter vários parâmetros de linha de comando, que nos permitem definir valores diferentes para hiperparâmetros de nosso modelo durante o treinamento:
--data_folder, que especifica o caminho para o conjunto de dados--batch_sizepara usar (o padrão é 128)--hidden, o tamanho da camada oculta (o padrão é 100)--dropoutpara usar após a camada oculta
Para enviar o experimento com os parâmetros fornecidos, primeiro precisamos criar o objeto Estimator para representar o nosso script:
script_params = {
'--data_folder': ws.get_default_datastore(),
'--hidden': 100
}
est = Estimator(source_directory='.',
script_params=script_params,
compute_target=cluster,
entry_script='train_keras.py',
pip_packages=['keras','tensorflow'])
Nesse caso, especificamos apenas um hiperparâmetro explicitamente, mas é claro que podemos passar os parâmetros que quisermos para o script para treinar o modelo com hiperparâmetros diferentes. Além disso, observe que o avaliador define os pacotes pip (ou conda) que precisam ser instalados para que o script possa ser executado.
Agora, para executar realmente o experimento, precisamos executar:
exp = Experiment(workspace=ws, name='Keras-Train')
run = exp.submit(est)
Em seguida, você pode monitorar o experimento diretamente dentro do notebook imprimindo nossa variável run (é recomendável ter a extensão azureml.widgets instalada no Jupyter, se você estiver executando-o localmente) ou acessando o Portal do Azure ML:
Otimização de hiperparâmetros usando o HyperDrive
A otimização de hiperparâmetros envolve algum tipo de pesquisa de varredura de parâmetros, o que significa que precisamos executar muitos experimentos com diferentes combinações de hiperparâmetros e comparar os resultados. Isso pode ser feito manualmente usando a abordagem que acabamos de discutir ou pode ser automatizado usando a tecnologia chamada Hyperdrive .
No Hyperdrive, precisamos definir o espaço de pesquisa para hiperparâmetros e o algoritmo de amostragem, que controla a maneira como os hiperparâmetros são selecionados nesse espaço de pesquisa:
param_sampling = RandomParameterSampling({
'--hidden': choice([50,100,200,300]),
'--batch_size': choice([64,128]),
'--epochs': choice([5,10,50]),
'--dropout': choice([0.5,0.8,1])})
Em nosso caso, o espaço de pesquisa é definido por um conjunto de alternativas (choice), embora também seja possível usar intervalos contínuos com distribuições de probabilidade diferentes (uniform, normal, etc; mais detalhes podem ser encontrados aqui). Além de Amostragem Aleatória, também é possível usar Amostragem de Grade (para todas as combinações de parâmetros possíveis) e a Amostragem Bayesiana.
Além disso, também podemos especificar a Política de Encerramento Antecipado. Isso faz sentido se nosso script relata métricas periodicamente durante a execução. Nesse caso, podemos detectar que a precisão obtida por uma determinada combinação de hiperparâmetros é menor que a precisão mediana e encerrar o treinamento mais cedo:
early_termination_policy = MedianStoppingPolicy()
hd_config = HyperDriveConfig(estimator=est,
hyperparameter_sampling=param_sampling,
policy=early_termination_policy,
primary_metric_name='Accuracy',
primary_metric_goal=PrimaryMetricGoal.MAXIMIZE,
max_total_runs=16,
max_concurrent_runs=4)
Depois de definir todos os parâmetros para um experimento do Hyperdrive, podemos enviá-lo:
experiment = Experiment(workspace=ws, name='keras-hyperdrive')
hyperdrive_run = experiment.submit(hd_config)
No Portal do Azure ML, a otimização de hiperparâmetros é representada por um experimento. Para exibir todos os resultados em um grafo, marque a caixa de seleção Incluir execuções filhas:
Escolher o melhor modelo
Podemos comparar os resultados e selecionar o melhor modelo manualmente no portal. Em nosso script de treinamento train_keras.py, depois de treinar o modelo, armazenamos o resultado na pasta outputs:
hist = model.fit(...)
os.makedirs('outputs',exist_ok=True)
model.save('outputs/mnist_model.hdf5')
Tendo feito isso, agora podemos localizar o melhor experimento no portal do Azure ML e obter o arquivo .hdf5 correspondente a ser usado na inferência: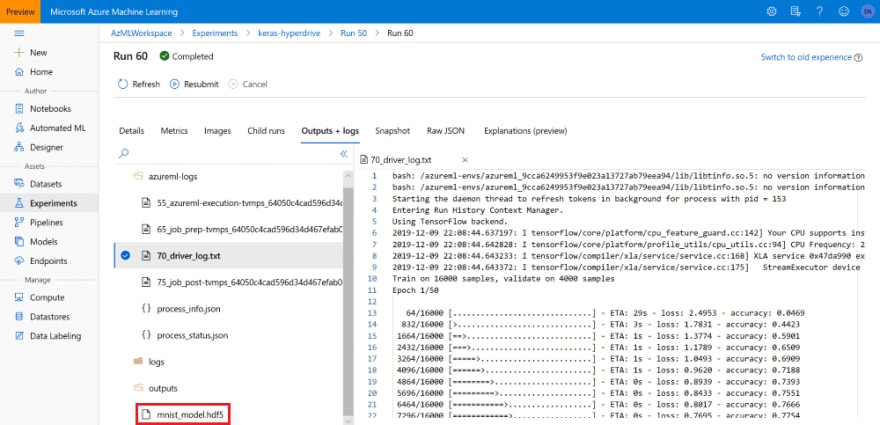
Como alternativa, podemos usar o Gerenciamento de Modelos do Azure ML para registrar modelo, o que nos permitiria manter um melhor controle sobre ele e usá-lo durante a implantação do Azure ML. Podemos encontrar o melhor modelo programaticamente e registrá-lo usando o seguinte código:
best_run = hyperdrive_run.get_best_run_by_primary_metric()
best_run_metrics = best_run.get_metrics()
print('Best accuracy: {}'.format(best_run_metrics['Accuracy']))
best_run.register_model(model_name='mnist_keras',
model_path='outputs/mnist_model.hdf5')
Conclusão
Aprendemos como enviar experimentos do Azure ML programaticamente por meio do SDK do Python e como executar a otimização de hiperparâmetros usando o Hyperdrive. Embora leve algum tempo para ser usado para esse processo, em breve você perceberá que o Azure ML simplifica o processo de ajuste do modelo, quando comparado a fazer isso “manualmente” em uma Máquina Virtual de Ciência de Dados.


