
Aquele em que você obtém conselhos para tornar seus fluxos de trabalho mais reproduzíveis
A explosão do Machine Learning e das soluções de IA é inegável. Há uma infinidade de coisas habilitadas por IA, desde a otimização de diagnósticos médicos até processos de RH e de fabricação de cerveja.Mas, graças a essa explosão, também percebemos que o processo de desenvolver produtos e introduzi-los no mercado é muito difícil. E não levou tanto tempo até começarmos a ver estes tipos de artigo aparecendo em todos os lugares:

https://www.wired.com/story/artificial-intelligence-confronts-reproducibility-crisis/

Hutson M., revista Science, fevereiro de 2018, vol. 359 pp. 725
1. O que é a reprodutibilidade e por que nos preocupamos?
Um resultado é reproduzível quando as mesmas etapas de análise executadas no mesmo conjunto de dados produzem consistentemente a mesma resposta.O Machine Learning reproduzível pode evitar erros e custos significativos no futuro. Além disso, ele facilita as tarefas de rastrear e explicar os insights/previsões gerados.
Além disso, trabalhar de maneira reproduzível facilita os processos de colaboração e revisão, garante a continuidade do seu trabalho e mantém o conhecimento institucional e as provas futuras de seu trabalho. Isso é extremamente importante porque, na maioria das vezes, não trabalhamos sozinhos, mas com um grupo de cientistas de dados, engenheiros de software e muitos outros stakeholders.
A verdade é que a reprodutibilidade em Machine Learning é um problema que todos os praticantes enfrentam diariamente.
Você já se fez uma das perguntas a seguir?
- Qual versão do conjunto de dados foi usada para treinar este algoritmo?
- Qual versão do algoritmo/modelo temos em pesquisa e desenvolvimento/preparo/produção/foi publicada no documento?
- Mantivemos o controle de todos os parâmetros e recursos que exploramos e dos modelos de linha de base?

Foto de autoria de Paolo Nicolello no Unsplash
Acredite, todos passamos por isso.
Portanto, sem mais delongas, vamos nos aprofundar em como tornar seus fluxos de trabalho mais reproduzíveis.
2. Como identificar os principais participantes
A base dos fluxos de trabalho reproduzíveis está na capacidade de rastrear e reproduzir os seus dados, o ambiente computacional e o código.Portanto, você observará que a maioria das recomendações aqui é relacionada a esses três ativos críticos:

Não vou me aprofundar muito sobre isso (pois isso merece uma postagem exclusiva). Mas, idealmente, você deseja tornar todo o seu trabalho reproduzível em três níveis:
- Metodologia: por exemplo, como fazer para formular seus experimentos e provar ou refutar sua hipótese.
- Modelo/algoritmo (embora o Machine Learning vá muito além dos modelos que são implantados). Por exemplo, explique a complexidade do seu algoritmo, o workspace que você está abrangendo e os critérios pelos quais os seus hiperparâmetros foram escolhidos.
- Infraestrutura: aqui, convém que você assegure deseja garantir a existência de uma infraestrutura robusta para que outras pessoas acessem seus dados e executem seu código. É preciso também que você descreva o hardware que utilizou (ou seja, a GPU).

3. Sempre saiba o que você espera dos seus dados.
Todos nós sabemos o quanto dados de boa qualidade são vitais para um aprendizado de máquina confiável e de boa qualidade. Portanto, sempre devemos saber o que estamos esperando de nossos dados, em todos os momentos: quais tipos, distribuições, intervalos e esquemas.
Uma das minhas ferramentas favoritas para fazer isso é a Great Expectations, pois ela se integra a outras ferramentas que uso como Spark, Airflow, Jupyter Notebooks e pandas (entre outras). Ela é uma excelente ferramenta para validação, teste e documentação de dados.
Por exemplo, se você tiver uma fonte de dados brutos na qual faça alguma manipulação antes de armazená-la em um banco de dados, poderá adicionar várias etapas de validação para os dados de entrada e de saída.

Se você estiver coletando dados de APIs de terceiros, poderá usar o esquema JSON para validar os dados com base no metaesquema.
4. Desenvolva pipelines.
A melhor maneira de manter o controle de todas as suas saídas, entradas, métricas, modelos e dados mesmo antes de usar ferramentas especiais é a capacidade de controlar cada tarefa que você está executando.
Muitas ferramentas permitem que você crie pipelines robustos. Muitos deles giram em torno do conceito de grafos direcionados acíclicos. Alguns dos meus favoritos são:
- Dagster: descobri que é extremamente fácil de usar e tem integração nativa com o Jupyter (Windows!).
- Airflow: esse projeto do Apache Incubator tornou-se muito popular. A interface do usuário torna muito fácil ter uma visão geral dos DAGs e dos respectivos status.
Isso adiciona muito mais complexidade:
No entanto, se você decidir implementar seus pipelines, mantenha esta regra geral em mente:
✨ Dica especial: divida suas tarefas em unidades atômicas de trabalho. Nelas, cada nó de seu DAG ou cada etapa em seu pipeline realiza uma única tarefa.
Isso ajuda a evitar o problema de “alterar qualquer coisa equivale a alterar tudo” (Scully et al).
5. O ML adora a aleatoriedade, então acostume-se com isso.
Há aleatoriedade em tudo:
- Inicializações aleatórias
- Argumentações aleatórias
- Introduções de ruído aleatórias
- Embaralhamentos de dados
O conselho sensato que você encontrará em qualquer lugar é sempre definir e salvar sua semente.
A solução: corrigir as divisões de treinamento e validação antes do treinamento. Se você usar métodos como test_split_train do scikit-learn, precisará também especificar o argumento seed.
6. Hiperparâmetros em toda parte
Encontrar os hiperparâmetros corretos para seus modelos pode ser um processo bastante complexo. Eles podem ser particularmente problemáticos quando você está executando vários experimentos com diferentes arquiteturas de rede.
✨ Dica especial: como regra prática, não mantenha o controle apenas dos parâmetros, mas também das métricas de saída de cada modelo associado e da sua linha de base/processo de seleção.
Um exemplo excelente de como controlar seus hiperparâmetros de maneira confortável pode ser encontrado no exemplo de ajuste de hiperparâmetros distribuídos do Pachyderm.
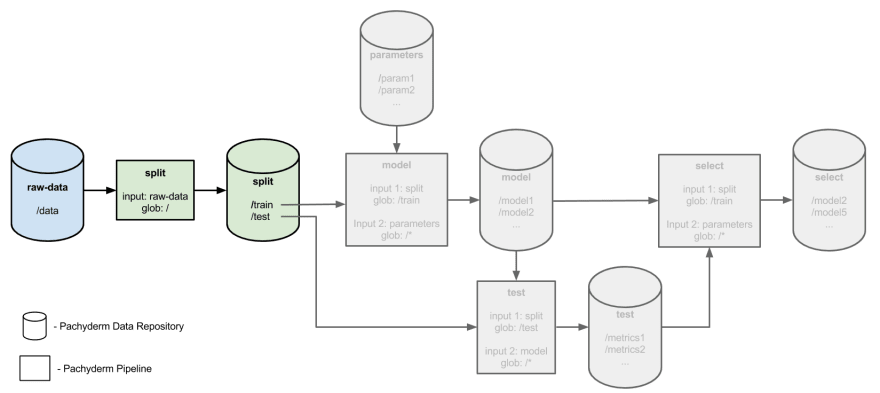
O uso de pipelines para dividir, treinar, testar e selecionar os modelos e hiperparâmetros facilita muito o controle das saídas em todos os estágios, bem como a geração de relatórios sobre a lógica por trás do porquê de você escolher hiperparâmetros específicos.
- Controle de versão e desacoplamento de dados.
Com que frequência você trabalhou em trechos de código que tinham linhas como esta:
import pandas as pd
df = pd.read_csv("../../../data.csv")
Nesse cenário, os dados e o código estão estreitamente ligados. Para garantir a reprodutibilidade, convém que você mantenha o controle do seu código e de suas versões de dados. Isso deve ser feito não apenas para as saídas finais, mas também para os resultados intermediários.
Imagine que você tenha um fluxo de trabalho como este:
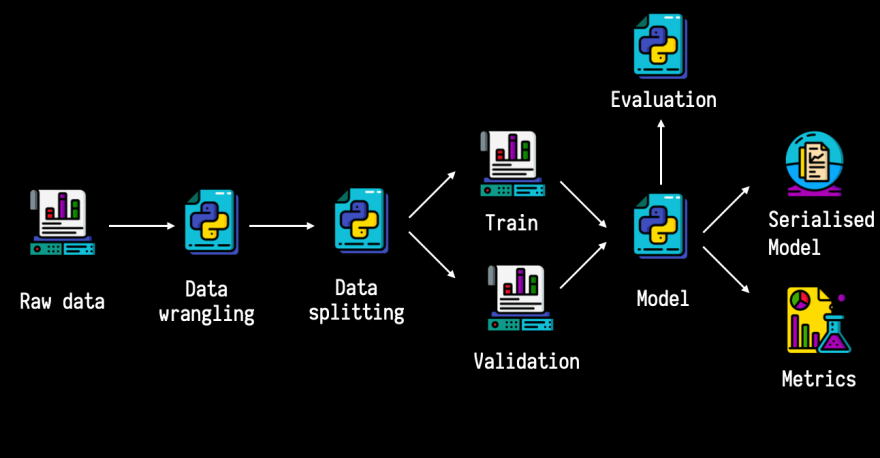
Embora esse seja um pipeline um pouco simplificado, ainda há várias saídas que você deseja controlar (dados, código e arquivos serializados).
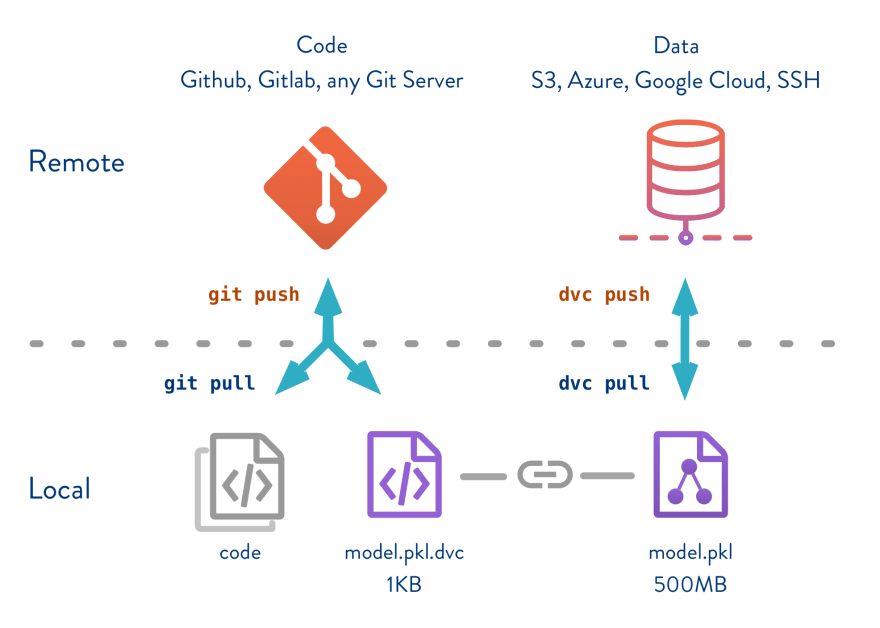
Uma excelente ferramenta para isso é o dvc, que permite manter o controle de todos os seus ativos com o Git sem armazenar seus dados no Git.Isso permite que você desacople dados, código e as respectivas versões para garantir a reprodutibilidade:
7. Teste
O teste no Machine Learning pode ser bastante complexo. Mais uma vez, não vou me aprofundar muito sobre isso porque essas estratégias de teste merecem uma postagem própria. Aqui está uma lista de verificação de estratégias de teste e itens cuja testagem você precisa considerar:
- Testes de contrato e chamadas à API em relação aos esquemas de dados
- Testes de integração para seus pipelines
- Testes de regressão
- Testes de unidade: teste seus métodos e transformações
- Testar se os pesos e as saídas do modelo são numericamente estáveis
- Reprodutibilidade entre ambientes: desenvolvimento, preparo e produção. As previsões entre elas devem ser as mesmas.
✨ Dica especial: um pacote que eu uso com muita frequência é o Hypothesis para testes baseados em propriedades. Ele não apenas simplificou as estratégias de teste, mas também aumentou minha confiança nos testes.
Há extensões para o Hypothesis que vale a pena verificar: https://hypothesis.readthedocs.io/en/latest/strategies.html.
8. Ambientes reproduzíveis
Para que uma parte do trabalho seja reproduzível, o ambiente computacional em que ele foi conduzido deve ser capturado para que outras pessoas possam replicá-lo.
Muitas ferramentas permitem que você crie ambientes reproduzíveis ou pelo menos que chegue perto disso.
Dependendo dos projetos nos quais estou trabalhando, tenho a tendência de misturar algumas destas ferramentas:
E ainda sou fã do Make, pois ele é fantástico.
✨ Dicas especiais:
- Não há uma resposta que se ajuste a todos os casos. Escolha o método mais apropriado para seu projeto a fim de capturar seu ambiente computacional
- Capture seu ambiente computacional: recomendo fixar não apenas as principais dependências, mas também as subdependências, bem como usar uma ferramenta com resoluções de dependência (pip-tools, pipenv and Poetry são ferramentas adequadas para fazer isso)
- O seu ambiente computacional capturado deve ser compartilhado junto com seu código e seus dados, se possível
9. Automatizar
Muitos erros podem ser introduzidos quando dependemos muito do humano no processo para nossos fluxos de trabalho.Assim, sempre que for possível automatizar as coisas, isso não apenas economizará tempo, mas otimizará seus fluxos de trabalho e aumentará sua confiança.
Algumas ótimas ferramentas que uso para a automação são:
- Tox – para testes automatizados
- Nox – para automação de teste flexível
- Invoke – execução de tarefas de uso geral (bastante semelhante ao Make, mas específico para o Python)
- Repo2docker – criar contêineres do Docker com base em repositórios do GitHub
- Binder – criar ambientes interativos reproduzíveis de repositórios do GitHub
- GitHub Actions – integração e entrega contínuas, bem como automação de fluxo de trabalho
✨ Dica especial: comece a automatizar as partes mais importantes (implantação, criação de contêiner, teste) e parta daí.
10. Consistência e padrões
Com a infinidade de ferramentas e fluxos de trabalho que existem, não há uma solução universal para o problema de reprodutibilidade.
Mas o que descobri é que a consistência é fundamental. Aqui estão minhas últimas ✨ dicas especiais:
- Tenha uma estrutura de projeto consistente. Você pode usar ferramentas como o CookieCutter Data Science.
- Siga os padrões de codificação:
- Documento e documentação como código.
- Muitas pessoas não gostam de escrever documentação. Mas algo que comecei a fazer há algum tempo é tratar documentos como código (bem, quase). Eu crio todos os meus documentos por meio de meus pipelines de integração contínua e também executo testes neles.
- Como escolher ferramentas:
- Mencionei muitas ferramentas aqui. Mas cada uma delas vem com uma curva de aprendizado e truques que você precisa aprender. Escolha a que funciona melhor para você e aprenda bem, em vez de tentar aprender a usar todas as ferramentas.
Isso é tudo! Essas são algumas dicas práticas para ajudar você a começar a usar aprendizado de máquina reproduzível.
Você tem alguma outra dica que eu deixei de fora? Avise-me nos comentários.

Autora: Tania Allard


